如何通过BeisenCloud创建索引
常见概念
BeisenCloud是一个PaaS平台,基于此平台能快速开发多终端自动适应的系统。BeisenCloud赋予系统诸多的可扩展能力。本文档仅从开发角度阐述如何开始一个基于BeisenCloud站点的开发。 完成一个站点的开发需要在平台host站点,创建应用、对象、表单、身份等步骤。
Beisencloud抽象了数据的存储,数据的索引,数据最终的渲染过程,让开发人员更可以更专注于业务的开发。
关键知识
分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行切词的一种技术。
Elasticsearch包含各种分词,你甚至可以自己写插件进行自己的分词。通过我们使用的比较多的分词器:
- Standard :就是无脑的一个一个词(汉字)切分,英文通过空格切分,特殊字符 空格,@,切分文本。“,”不切分。
- English : 对英文更加智能,可以识别单数负数,大小写,过滤stopwords(例如“the”这个词)等
- IK:中文分词器。支持各种中文短语分词,不是硬生生按单字分词。
- keyword_chinese_collator:是一个特殊的分词插件,理论上它并不是一个分词器,它主要提供功能是针对中文的自然语言排序。也就是音序排序。
我们通常开发对对于有分词要求的字段通常情况下均是使用Standard分词器。
技术内幕
应用:应用是一个大范围的概念,在目前北森体系下基本上是产品概念的切分。同时它也是对我们ES中索引这个概念的一个描述。
对象:对象是产品范围下各种子业务的对象模型。同时也是对我们ES中Type的描述。
字段:字段就很好理解了,不同的子业务模型中需要存储的字段需要索引的字段均通过字段来定义。
我们在创建一个标准字段的
- 第一步:选择字段类型
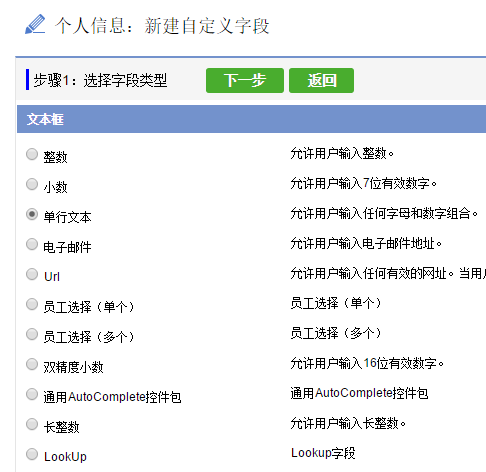
这个字段类型,定义了你在数据存储(cassandra)和索引(Elasticsearch)中对应的字段类型,整形,字符串还是日期。
- 第二步:创建字段基本信息
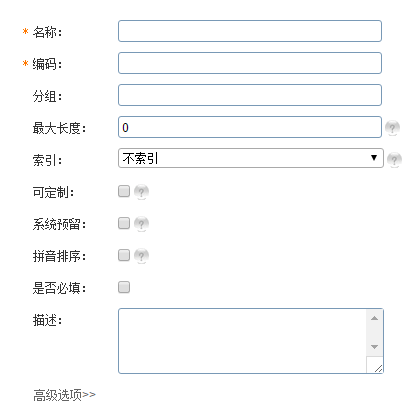
目前第二步中的相关设置目前只有
索引:用来标识该字段是否可以用来搜索。是分词搜索还是非分词搜索。
拼音排序:拼音排序是一个特殊的分词类型。“keyword_chinese_collator”当你为每个字段选择分词索引,并选择这个分词器时就可以实现中文音序排序。
和ES索引mapping中有对应关系,编码也可以说有,只是字段的名称。
经验技巧
1.由于mappig上的字段属性是不允许修改的,所以如果你不小心创建错了一个字段的名称,分词类型,是否索引代价是很大的。这里我们有低成本和高成本两种不同的做法。
- 重新创建一个其他名称的同含义字段,旧字段依然保留在现有索引上。
- 删除该错误字段,并删除索引mapping,全部重新创建mapping和重建索引。
第二种方法是成本异常高昂的,特别是在索引数据量及其庞大的时候是需要付出产痛的代价,所以我们要尽量避免创建补正确的字段,特别是在上线过程中要再三确认。
2.在一个Index下的不同Type中(在一个应用的不同对象中),如果你有同名的field字段,务必保持在不同的type下你的同名字段的属性一定要是一致的。否则在不同的对象上进行搜索的时候会出现很多奇怪的问题。同时ES也并不建议在不同的type(对象中)出现同名字段。
实例
下面我们介绍下如何在Beisencloud中创建我们需要的索引过程:
创建应用: 应用是BeisenCloud对产品对象的水平切分对象。比如现在我们是在招聘系统中处理应聘者简历信息,那么我们需要先为招聘产品创建一个应用。Recruitment
创建对象: 对象是BeisenCloud应用下业务模型对象的切分。比如我们现在要建立的应聘者简历对象,它正式一个完全符合的ApplicantProfile对象。
创建字段: 一个应聘者对象包含了很多信息,姓名,邮箱,手机号,学历等等各个维度的不同信息,我们需要根据具体的业务场景业务一一创建成对应的对象字段。