倒排索引
事实上,常用的索引方式有3中:倒排,后缀数组和签名文档。倒排索引已经被当前大多数信息系统所广泛应用。它特别符合人们的思维习惯,同事它对关键字的检索非常有效。后缀数据在短语查询时,具有较快的速度,只是构造和维护这样的索引非常复杂。签名文档的方式已经基本上被淘汰了。
1. 什么是倒排
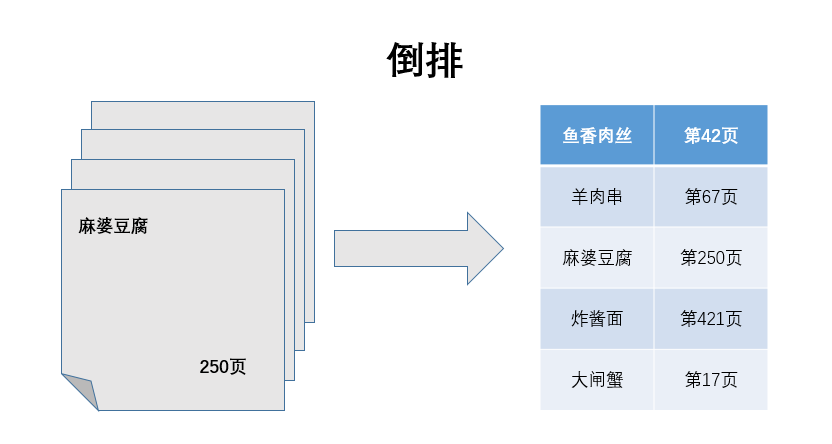
当我们在阅读一本书的时候,通常使用页数来查找相关内容。每一页上具有一定数量的文本,这些文本记录的信息。当使用倒排方式后,不再有整页整页的信息,信息被分割成一个个的关键字,并辅以关键字所在的原书中的页数,而构成一个倒排基本单位。
例如,一本旅游类书籍的第250页讲诉了“麻婆豆腐”的来历,在经过倒排后,“麻婆豆腐”被作为一个单独的关键字切分出来,保存在索引中,同时还带有其页码250,作为索引的内容。这样当信息系统检索“麻婆豆腐”这个关键字的时候,系统可以迅速的给出其页码,然后再到原书中取出相关页面文本内容。这种查找方式比从第一页开始线性匹配所有文本,找出包含有“麻婆豆腐”的页面内容快得多。
从理论上说,倒排是一种面向单词的索引机制。通常,由词和出现情况两部分组成。对于索引中的每个词,都跟随一个列表(位置表),用来记录单词在所有文档中出现的位置。
2.倒排的特点
在倒排索引中,关键字的数量并非随着文本内容的增长也线性增长。这因为不论多大数量的文本数据库,总能规范出一个关键词表搜到实际语言因素的限制,它的增长率在文本数据库达到一定规模后可以忽略不计。有人做过统计,对于1GB的文本信息来说,词汇表的大小在5MB左右。
可以试想,将一本书上所有文本均制作成关键字,并对其进行倒排,构建一个信息搜索系统。对其中的内容进行检索,在整个过程中,最消耗时间的应该倒排阶段。因为在倒排时,需要对文本进行分析,切词,还要构建索引结构,记录位置信息,同时维护内容。虽然这一阶段花时间,但是一旦完成,在搜索时将会大大节省时间。事实上,一个信息检索系统在建立索引时的速度是可以放宽的,因为这是在后台异步完成的,而其搜索速度才是影响用户最终体验的直接因素。